Figures
To insert a figure in a LaTeX document, you write lines like this:
\begin{figure}
\centering
\includegraphics[width=3.0in]{imagefile1}
\caption{Caption for figure}
\label{fig:sample_figure}
\end{figure}
The whole block is enclosed between \begin{figure} and \end{figure}. The command \includegraphics does the actual insertion of the image. Here the file name of the inserted image is imagefile1. If you are using LaTeX to process your document, .eps extension is appended automatically to the file name. If you are using pdfLaTeX, it appends .pdf, .png, or .jpg when searching for the image file.
By default, figures are looked for in the current directory (the one in which your .tex file is located). If you want to specify a path for the \includegraphics command, remember to use forward slashes (/) as directory separators, not backslashes. For example, if your figures are in a sub-directory named “figures” inside the current directory, you write something like this: \includegraphics[width=3.0in]{figures/imagefile1}.
You can also specify the width of the image. The height of the figure is scaled proportionally so the image doesn’t get distorted. Specify the width as a parameter (enclosed in brackets [ ]) to the \includegraphics command. Acceptable measurement units are for example in, mm, and cm. You can make the figure’s width equal to the width of paragraph text lines by using [width=\linewidth], or, for example, three quarters of the text width by using [width=0.75\linewidth].
Here we have used a \centering command to center the figure in the column. The \caption command gives a caption for the figure. We have also added a \label, which is useful when you want to refer to the figure in your text (see References).
Remember to always keep the commands in this order: First \includegraphics, then \caption, and finally \label. This way you get figure references right and captions underneath figures. Additionally, keep the \label and \caption commands always inside the \begin{figure}…\end{figure} structure.
You can specify the locations where the figure (or table) is allowed to be placed by using placement parameters. For example, to put a figure at the bottom of page, you type \begin{figure}[b]. To allow a figure to be placed only at the top of page, write \begin{figure}[t]. To allow both locations, use [tb]. Other options are described, for instance, in Chapter 9 of Online tutorials on LaTeX.
If you don’t yet know how to create EPS images for LaTeX documents, read the Creating figures tutorial.
Subfigures
If you want to divide a figure into many smaller parts, use the \subfigure command. First, you have to add this in the beginning of your .tex file:
\usepackage{subfigure}
Let’s add three small figures in place of one normal figure:
\begin{figure}
\centering
\subfigure[First caption]
{
\includegraphics[width=1.0in]{imagefile2}
\label{fig:first_sub}
}
\\
\subfigure[Second caption]
{
\includegraphics[width=1.0in]{imagefile2}
\label{fig:second_sub}
}
\subfigure[Third caption]
{
\includegraphics[width=1.0in]{imagefile2}
\label{fig:third_sub}
}
\caption{Common figure caption.}
\label{fig:sample_subfigures}
\end{figure}
The result is:

Write as many \subfigure commands as you need. \subfigure takes an argument (enclosed in brackets [ ]) which specifies the caption for that subfigure. You don’t need to write the labels (a), (b), (c), etc., because LaTeX adds them automatically. Then put the \includegraphics and \label commands between { and } of the subfigure. Here we use an image file named imagefile2.eps. We have also specified a width for each image using the optional width parameter of the \includegraphics command.
Note the \\ after the first subfigure. This command creates a line break. In this case, it separates the three subfigures into two rows. Without the \\ all the three subfigures may end up in just one row. You can try the \\ also in other places and see its effect.
Finally, we put one more \caption and \label. These are for the whole three-part figure element.
Tables
A table in LaTeX may look a bit scary bunch of code at first. But you can copy and paste the basic lines that are needed. Then inserting your own text into the table is a piece of cake. Here we go:
\begin{table}
\renewcommand{\arraystretch}{1.3}
\caption{Simple table}
\label{tab:example}
\centering
\begin{tabular}{c|c}
\hline
Heading One & Heading Two\\
\hline
\hline
Three & Four\\
\hline
Five & Six\\
\hline
\end{tabular}
\end{table}
The result will look like this (using IEEE’s style):

Hence it’s a table with two columns and three rows. Here is how you organize the text in a table: In each table cell write the the text that you want to appear in the cell. Then type & when you want to jump to the next column. A new table row begins when you type \\. You can insert horizontal lines using the command \hline.
Here we have specified the column format like this: \begin{tabular}{c|c}. Every letter c, l, or r denotes a column and | represents a vertical line between columns. c creates a column with centered text, l is for left aligned text, and r for right aligned. Thus, c|c creates two columns with centered text and a vertical line between them.
To get double lines between columns, use || instead of single |. To get no line between columns, omit the |. More columns can be added by using more c, l, or r letters. For example, this produces four columns with no vertical lines: lccc. Now the leftmost column is left aligned and the others are centered.
You may wonder about the strange line \renewcommand{\arraystretch}{1.3}. This is needed for adjusting the white space around text in the table cells. The value 1.3 produces quite a pleasing look.
If you want to have the caption underneath the table, move the \caption and \label lines after the \end{tabular} line. Remember that the \caption command must be before \label.
Double column figures and tables
If you are writing a two column document and you would like to insert a wide figure or table that spans the whole page width, use the “starred” versions of the figure and table constructs. Like this:
\begin{figure*}
\centering
\includegraphics[width=\textwidth]{imagefile1}
\caption{This is a wide figure}
\label{fig:large}
\end{figure*}
You can use also subfigures inside figure*. An adequate width specifier for a double column figure is width=\textwidth. This makes the figure wide enough to span the whole body width (all columns) of the page.
A double column table is created in a similar way by using \begin{table*} and \end{table*}. Write the contents of the table in the usual way.
Note that double column figures and tables have some limitations. They can’t be placed at the bottom of pages. Additionally, they will not appear on the same page where they are defined. So you have to define them prior to the page on which they should appear.
Equations
Short mathematical expressions can be inserted within paragraph text by putting the math between $ signs. For example:
... angle frequency $\omega = 2\pi f$ ...
This is called an inline equation. The result is:  .
.
In equations, the normal text symbols are written as such, for example 2 and f. Greek symbols are named for example \alpha, \beta and so on. You don’t need to remember these because in WinEdt and TeXnicCenter you can use symbol toolbars, which have buttons for Greek letters and other math symbols.
Numbered equations are separate from paragraph text and LaTeX numbers them automatically. The contents are written using the same ideas as inline equations but now we write \begin{equation} and \end{equation} instead of $ signs. For example:
\begin{equation}
\label{eq:kinetic_energy}
E_{k} = \frac{1}{2}mv^{2}
\end{equation}
The result is:

Here we learn some structures which are often used in equations: The \frac command creates a fraction. Write the contents of the numerator and denominator inside the curly braces. Subscripts and superscripts are created using _{} and ^{}. (If the content of the subscript or superscript is a single symbol, you can omit the curly braces like this: E_k and v^2.)
Remember that an empty text line produces a paragraph break. Thus, omit empty lines before and after your equations, unless you really need a paragraph break there. This way you can easily explain the meaning of the variables (“where m is the mass and v is…”) so that the word “where” won’t start a new paragraph and won’t become indented.
You can freely type spaces in equations. LaTeX ignores extra spaces and determines automatically where (and how wide) space is needed (for example, on both sides of the = sign). However, line breaks are not allowed. Spaces are needed also to separate LaTeX commands. For instance, if you want to print  , you must type
, you must type \beta A, not \betaA. The latter one won’t compile because LaTeX is looking for a command named betaA.
Occasionally spaces in equations may need some fine adjustment. For example, consider the following two equations:

Equation (1) has been created by simply typing f_{res} = 500 MHz. It seems to have several problems:
- The unit “MHz” and the subscript “res” have an incorrect spacing between letters. This is a common problem in variable names, subscripts, and units that consist of several letters. LaTeX understands “res” as a product of variables r, e, and s. Thus it adds a small space between each multiplicand. To fix the problems, write
\mathrm{res} and \mathrm{MHz} . The “mathrm” stands for math “roman” (upright) font style.
- The unit “MHz” and the subscript “res” should be typed with upright font, not italic. The aforementioned
\mathrm command fixes this problem. If you, instead, want to use italic font, replace \mathrm with \mathit.
- In equation (1), there is hardly any space between the number and the unit. LaTeX has thought that you want to multiply 500 times “MHz” and thus it removes all spaces you write here. To force a visible space, use command
\,.
Here is the final fixed content of the equation, which produces the result (2) as shown above:
f_{\mathrm{res}} = 500 \, \mathrm{MHz}
If you have problems with a long equation that is wider than the space available on the page, you can split your math on several lines like this: First put \usepackage{amsmath} in the beginning of your LaTeX file. Then use \begin{split}...\end{split}:
\begin{equation}
\label{eq:long_equation}
\begin{split}
F &= a + b + c + d + e + f + g \\
&+ h + i + j + k + l + m \\
&= a + \ldots + m \\
&= 0
\end{split}
\end{equation}
The result looks like this:

To start a new line in your equation, add \\ to the end of the line. Additionally, put an & before the signs that should be aligned in a straight vertical line. Here we have aligned the = and + symbols.
Like shown above, amsmath can often provide a LaTeX solution to more demanding math problems. See the documentation of amsmath at TeX Catalogue Online or at CTAN.
原文链接:http://www.electronics.oulu.fi/latex/examples/example_3/index.html

































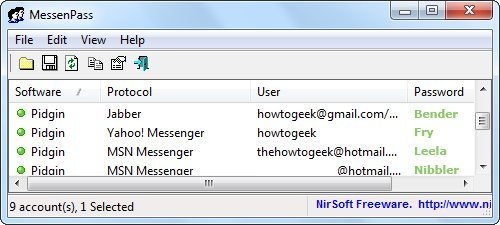
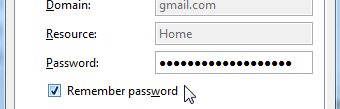 基 本上任何需要登录的软件都会提供一个保存密码的选项给你.如果你使用了它,你的密码便如明文一般了.即使软件在后台将你的帐号加密保存,一般情况下它也仅 仅是使用固定的值将其加密,逆向工程很容易便可以破解出来 — 而现在不仅仅是可能性的问题,已经的确有人做出了这样的密码恢复程序.
基 本上任何需要登录的软件都会提供一个保存密码的选项给你.如果你使用了它,你的密码便如明文一般了.即使软件在后台将你的帐号加密保存,一般情况下它也仅 仅是使用固定的值将其加密,逆向工程很容易便可以破解出来 — 而现在不仅仅是可能性的问题,已经的确有人做出了这样的密码恢复程序.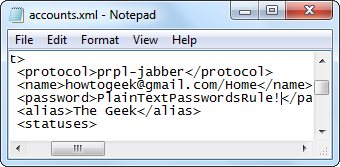 你没看错,你最喜爱的开源多协议的即时通讯客户端在使用明文保存你的密码.你不信吗? 那好,用你最顺手的编辑器打开 %appdata%.purpleaccounts.xml ,你会看见你的密码就在这里–以任何人都可以直接阅读的方式.
你没看错,你最喜爱的开源多协议的即时通讯客户端在使用明文保存你的密码.你不信吗? 那好,用你最顺手的编辑器打开 %appdata%.purpleaccounts.xml ,你会看见你的密码就在这里–以任何人都可以直接阅读的方式.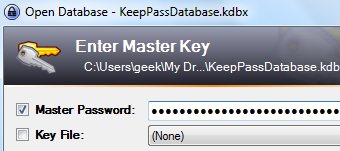 唯 一真正安全的保存密码的方式是使用密码管理软件,它可以安全的记录你的密码,并以强大的主密码来保护你所有其他的密码.不过,如果你设置了一个简单的主密 码,它可能很容易被暴力破解攻破.不要被错误的安全感误导了,使用单一的密码并非代表万无一失.你的密码管理软件至少要有10位字母/数字以确保安全. (猫叔乱入:猫叔的KeePass主密码是16位混合大小写,数字,符号的密码 =w=)
唯 一真正安全的保存密码的方式是使用密码管理软件,它可以安全的记录你的密码,并以强大的主密码来保护你所有其他的密码.不过,如果你设置了一个简单的主密 码,它可能很容易被暴力破解攻破.不要被错误的安全感误导了,使用单一的密码并非代表万无一失.你的密码管理软件至少要有10位字母/数字以确保安全. (猫叔乱入:猫叔的KeePass主密码是16位混合大小写,数字,符号的密码 =w=)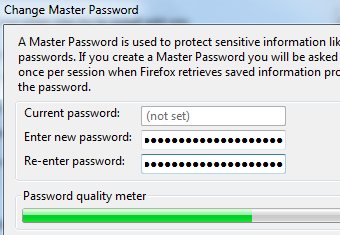 如果你打算用Firefox来保存你各种网上帐号,你应该确保开启了主密码保护.
如果你打算用Firefox来保存你各种网上帐号,你应该确保开启了主密码保护.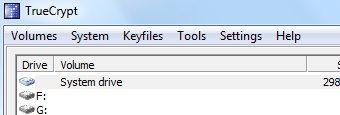 不 管你是否使用密码管理软件还是压根不保存密码,你都可以使用TrueCrypt创建一个独立的加密TrueCrypt磁盘并使用携带版软件(aka.绿色 软件)以保证安全.更极端的做法是用TrueCrypt加密整个硬盘,你将会在每次启动时要求输入密码,不过你可以放心了,你所有的东西都是加密的,就算 你用明文的脚本来保存密码.
不 管你是否使用密码管理软件还是压根不保存密码,你都可以使用TrueCrypt创建一个独立的加密TrueCrypt磁盘并使用携带版软件(aka.绿色 软件)以保证安全.更极端的做法是用TrueCrypt加密整个硬盘,你将会在每次启动时要求输入密码,不过你可以放心了,你所有的东西都是加密的,就算 你用明文的脚本来保存密码.
近期评论